
2025-04-24
Recently I ran into an interesting challenge in SQL when working in BigQuery that I was not previously aware of. I was generating a random number in a single CTE (common table expression) and I then referenced that CTE multiple times later in the query.
I realized that the random number in one CTE reference wasn't matching what should have been the same random number in the other CTE reference. You would think that these random numbers would be generated a single time when this CTE was created. Then, referencing them multiple times later would produce consistent random numbers between references.
with sample_data as (
select id, row_number() over (order by rand()) as random_row_num
from unnest(['a', 'b', 'c', 'd']) as id
)
select
a.id as id_a
,a.random_row_num as row_num_a
,b.id as id_b
,b.random_row_num as row_num_b
from sample_data as a
inner join sample_data as b
on a.id = b.id
order by id_a;
After some digging, it turns out that CTEs can be evaluated each time they are referenced. So each time I was referencing the CTE, it was reevaluating the CTE and regenerating new random numbers.
Here is how Google explains it in their documentation:
They say that the query optimizer may attempt to detect parts of the query that could be executed only once, but this might not always be possible.
This is how this looks in BigQuery when we create random numbers in one CTE and reference it multiple times. We're matching on the IDs but the random row numbers generated in the CTE are different in the two different times that we reference it.
with sample_data as (
select id, row_number() over (order by rand()) as random_row_num
from unnest(['a', 'b', 'c', 'd']) as id
)
select
a.id as id_a
,a.random_row_num as row_num_a
,b.id as id_b
,b.random_row_num as row_num_b
from sample_data as a
inner join sample_data as b
on a.id = b.id
order by id_a;
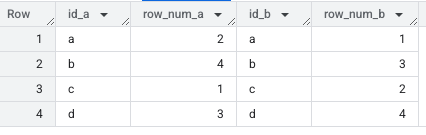
In order to get around this, we can just use a temporary table.
create temporary table sample_data as (
select id, row_number() over (order by rand()) as random_row_num
from unnest(['a', 'b', 'c', 'd']) as id
);
select
a.id as id_a
,a.random_row_num as row_num_a
,b.id as id_b
,b.random_row_num as row_num_b
from sample_data as a
inner join sample_data as b
on a.id = b.id
order by id_a;
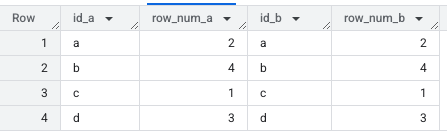
Now we can see that the random row numbers are matching between the IDs from each of the separate references to the temporary table.
This is also the case in DuckDB. Referencing a CTE multiple times causes it to be reevaluated each time, resulting in different random numbers for the same IDs.
with sample_data as (
select id.unnest as id, row_number() over (order by random()) as random_row_num
from unnest(['a', 'b', 'c', 'd']) as id
)
select
a.id as id_a
,a.random_row_num as row_num_a
,b.id as id_b
,b.random_row_num as row_num_b
from sample_data as a
inner join sample_data as b
on a.id = b.id
order by id_a;

Similar to BigQuery, in DuckDB we can just use a temporary table to solve the issue.
create or replace temporary table sample_data as (
select id.unnest as id, row_number() over (order by random()) as random_row_num
from unnest(['a', 'b', 'c', 'd']) as id
);
select
a.id as id_a
,a.random_row_num as row_num_a
,b.id as id_b
,b.random_row_num as row_num_b
from sample_data as a
inner join sample_data as b
on a.id = b.id
order by id_a;

I haven't tried this in any other databases, but it seems likely that others would act similarly. It's probably best to assume that if you need to reference a CTE multiple times and it contains something non-deterministic, you should opt for a temporary table instead.